Building an ML model in a notebook is the easy part. This article walks through what actually happens when you try to ship that model to real users, the practices, tools, and mindset shifts that fall under the umbrella of MLOps (and now LLMOps)
ML in research vs in production
Understanding ML systems will be helpful in designing and developing them. In this section, we’ll go over how ML systems are different from both ML in research (or as often taught in academia or school ) and traditional software
As the use of ML in the industry is still a bit new, most people with ML expertise have gained it through academia: taking courses, doing research, reading papers. If that describes your background, you might find it hard to understand how to use ML systems in the real world and deal with all the solutions to the problems they cause. ML in production is very different from ML in research. the next table shows the major differences
| Research | Production | |
|---|---|---|
| Objectives | Model performance (accuracy, ..) | Different stakeholders have different objectives |
| Computational priority | Fast training, high throughput | Fast inference, low latency |
| Data | Static | Constantly changing over time |
| Fairness | Good to have (sadly) | Important |
| Interpretability | Good to have | Important |
- Stakeholders such as :
- ML team : highest accuracy
- product : fastest inference
- sales : sell more
- manager : maximizes profits
moving from research to production isn’t just a technical step but it is a cultural shift. according to NVIDIA[2] MLOps is often confusing because it is :
- broad : it covers everything from data management to business culture
- diverse : there isn’t one “standard” way to do it yet, so different companies use different languages to describe the same problem
- complex : practitioners often focus on the “accidental complexity” of their specific tools rather than the essential complexity of the problem itself
MLops is a set of practices that helps data scientist and engineers to manage the ML life cycle more efficiently , it aims to bridge the gap between development and operations for ML. the goal of MLOps is to ensure that ML models are developed, tested , and deployed in a consistent and reliable way
Ops in MLOps comes from DevOps short for Developments and Operations. To operationalize something means to bring it into production, which includes deploying, monitoring, and maintaining it.
The main differences between MLOps and DevOps is that :
Devops is a set of practices that helps organizations to bridge the gap between software development and operations teams. MLOps is a similar set of practices that specifically addresses the needs of ML models, main key differences includes :
- scope : DevOps focuses on the software dev life cycle while MLOps focuses on the ML life cycle
- complexity: Machine Learning models are more complex than traditional software applications which require specific tools and techniques for development and deployment
- data : ML models rely on data for training and inference, this can introduces challenges for managing and processing data
- regulations: ML models are sometimes be subject to regulatory requirements which may impact the development and deployment process
even though they have some differences, they share a lot of common principles, such as the importance of automation , continuous improvements, collaboration. Google [1] mentioned that organizations that have adopted DevOps practices can leverage those practices when implementing MLops
Benefits of MLOps
MLOps offers numerous benefits to organizations that adopt it, including:
- Improved efficiency: automates the ML life cycle, reducing time and effort
- Increased scalability: enables organizations to scale their ML operations more effectively, handling larger datasets
- Improved reliability: reduces the risk of errors, ensuring that ML models are reliable and accurate in prod
- Enhanced collaboration: provides a common framework and set of tools for data scientists, engineers and operations teams
- Reduced costs: can help organizations reduce costs
Vocabulary : CI: testing code + data + model CD: deploying model as a service CT (Continuous Training): the ML-specific addition
Basic components of MLOps [1]
MLOps consists of several components that work together to manage the ML life cycle, including:
1. Exploratory data analysis (EDA)
- Data visualization
- Data cleaning
- Feature engineering
2. Data prep and feature engineering
Data preparation and feature engineering are critical steps in the MLOps process. Data preparation involves cleaning, transforming, and formatting the raw data to make it suitable for model training.
A feature store is a centralized repository that stores, versions, and serves features for both training and inference. It solves a classic MLOps headache: making sure the features your model sees in production are computed the exact same way as during training (avoiding training-serving skew).
3. Model training and tuning
- Selecting the right ML algorithm
- Training the model
- Tuning the model
- Evaluating the model
4. Model review and governance
- Model validation
- Model fairness
- Model interpretability
- Model security
5. Model inference and serving
- Model registry: a versioned catalog of trained models with their metadata (training data, hyperparameters, metrics, lineage). It answers the question “which exact model is running in production right now, and can I reproduce it?”
- Model deployment
- Model serving
6. Model monitoring
Our models are designed to decay , the data will shift and the performance will drop and yes we can fight back. You can’t really fix what you can’t see for that we need monitoring which involves continuously monitoring the performance and behavior of the ML model in production. Tasks may include:
- logging : capture events and errors
- metrics : track key performance indicators (KPI)
- dashboards : visualize system health
- alerting : notify on anomalies/ model issues
- check the section [Myths of ML deployment] about data and concept drift
7. Automated model retraining
Automated model retraining involves retraining the ML model when its performance degrades or when new data becomes available. Automated model retraining includes:
- Triggering model retraining
- Retraining the model
- Evaluating the retrained model
From Notebooks to Production-Grade Code Real-world MLOps requires moving beyond messy notebooks to structured software. To ensure the reliability mentioned above, engineers should adopt robust design patterns like : type-safe data contracts (Pydantic), abstract interfaces for swappable models (ABCs), proper testing , and modular pipelines. I’ ll dedicate a future blogs to these patterns soon.
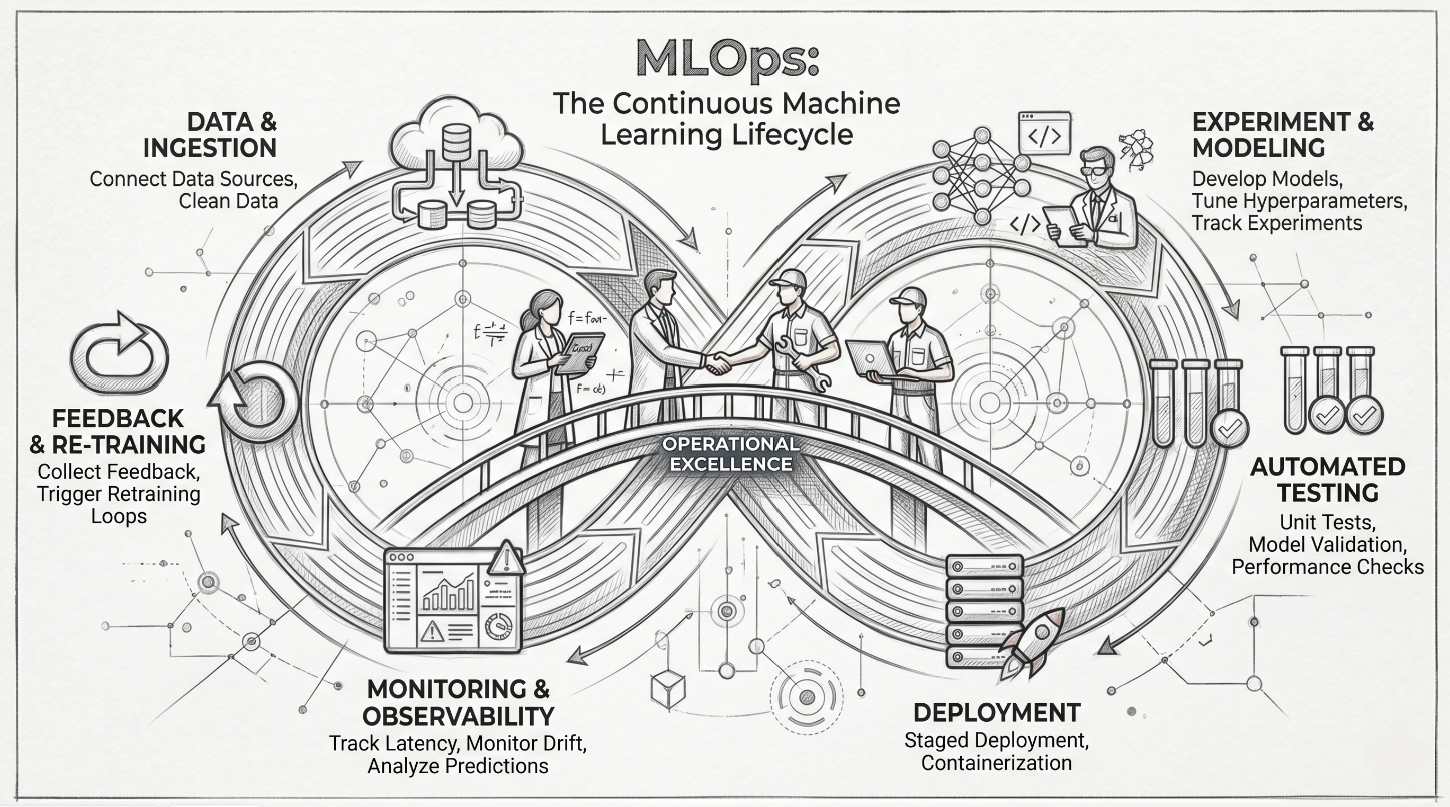
traditional baseline : core mlops lifecycle
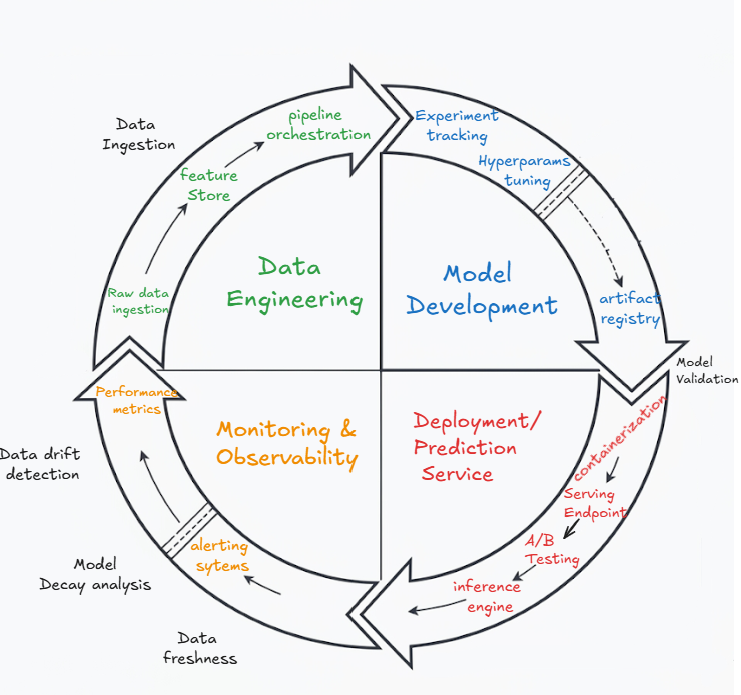
- you see one direction of the arrow but in reality it is much more complex than that
The next workflow shows 7 human processes each of which informs the next:
Notice the colored dots: different personas own different stages. Let’s meet them
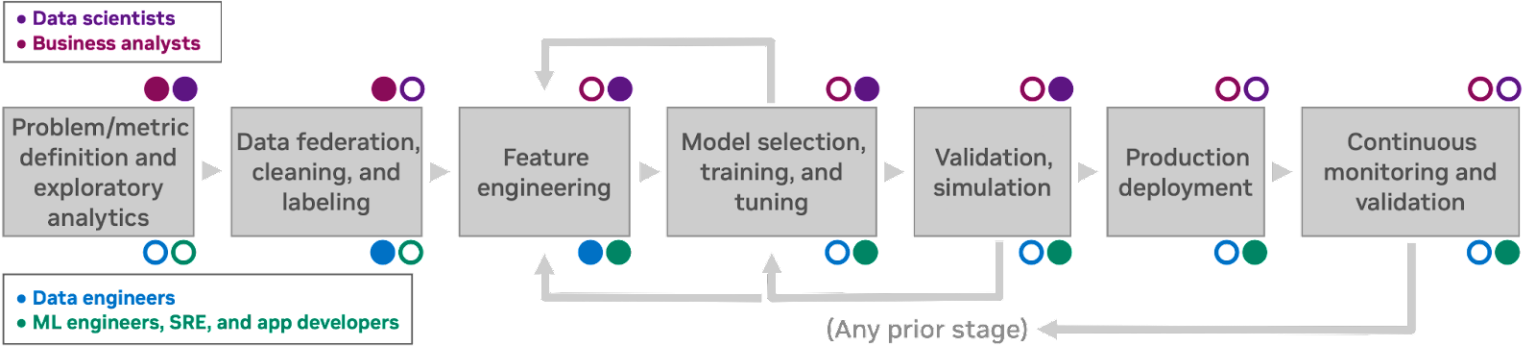
An example of a human-centric machine learning discovery and development workflow, with the relevant tasks, personas, and interactions
Who are the players in this Game ?
As AI matures, roles have become more specialized, according to Nvidia here is how the team usually looks :
- Data Scientists: The “experimentalists” who find patterns in data
- Data Engineers: The “plumbers” who make data available, secure, and organized at scale
- Machine Learning Engineers: The “builders” who focus specifically on developing and optimizing the production infrastructure
- Application Developers: The “integrators” who take the ML services and bake them into the final product
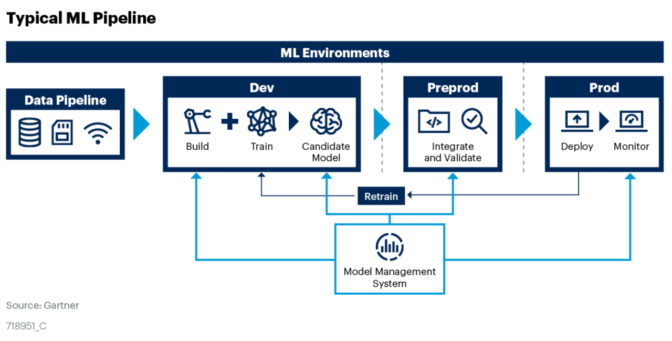
Gartner’s view of the machine-learning pipeline , source (NVIDIA blog)
Myths of ML deployment
The main myths and their realities: see Stanford MLsys seminars [Video] Machine learning production myths
| Myth | Reality |
|---|---|
| #1 You only deploy one or two ML models at a time | Enterprise applications require compound systems and ensembles of dozens of specialized models and tools |
| #2 If we don’t do anything, model performance remains the same. | Models degrade due to data distribution shifts; continuous monitoring is mandatory. |
| #3 You won’t need to update your models as much. | Continuous learning and online evaluation drive weekly, if not daily, updates to context and prompts. |
| #4 Most ML engineers don’t need to worry about scale. | LLMs introduce unprecedented computational bottlenecks and latency challenges in production. |
| #5 (LLMops-related) LLMs are plug-and-play and don’t need ‘Ops’. | LLMs are non-deterministic; they require Prompt Versioning and LLM-as-a-Judge evaluations to ensure that a simple prompt change doesn’t break the entire system’s logic |
Myth #1: Uber has thousands of models in production. At any given moment, Google[1] has thousands of models training concurrently with hundreds of billions parameters in size. Booking.com has 150+ models. A 2021 study by Algorithmia shows that among organizations with over 25,000 employees, 41% have more than 100 models in production
Fig shows a wide range of the tasks that leverage ML at Netflix.[3]
Different tasks that leverage ML at Netflix. Source: [Video]

Myth #2 mentions “data distribution shifts”, that umbrella term actually splits into two distinct phenomena:
Concept Drift: The statistical relationship between the input features and the target variable changes over time, meaning the “logic” of the model’s predictions is no longer valid. Data Drift: The underlying distribution of the input data changes (e.g., due to seasonal shifts or sensor changes), even if the fundamental relationship between those features and the output remains the same.
Matching the Solution to the Data
Not all MLOps is the same. The requirements change based on what you are processing
- Tabular Data: Often allows for automated labeling and simpler pipelines
- Unstructured Data (Video, Audio, Language): Requires much more manual human effort to label and complex infrastructure to process
- High-Stakes Systems: If the ML controls financial portfolios or medical decisions, it requires intense simulation and safety validation before it ever touches a user
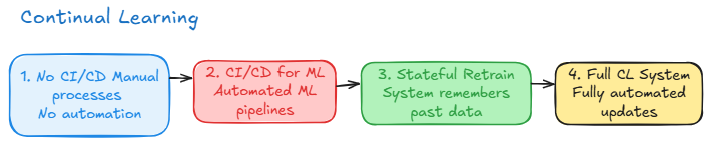
The 4 stages of ML maturity
scalability is not a feature you can add, it is a state you achieve by evolving through the 4 stages of continual learning (framework adapted from Chip Huyen’s Designing Machine Learning Systems). from manual scripts to full automation is a cultural transformation that bridges the gap between the data scientist’s focus on patterns and the ML engineer’s focus on infrastructure
- stage 1:
manual script based retraining; it is stateless where data is extracted manually and models trained in notebooks - stage 2 :
automated retraining; retraining is scheduled or trigged by time or metrics, but the deployment of the resulting artifacts is still manual - stage 3 :
automated deployment; now the pipeline includes automated testing and canary releases where the system is allowed to update the model in prod without human intervention - stage 4:
full automation (continual learning );system transitions to stateful training where the model updates continuously in response to performance triggers or new data streams
- “To be deployed, your model will have to leave the development environment. Your model can be deployed to a staging environment for testing or to a production environment to be used by your end users.”
The LLMOps pivot: hallucination and prompt versioning
LLMOps: is a specialized subset of MLOps which focuses specifically on the challenges and requirements of managing LLMs. while MLOps covers the general principles and practices of managing machine learning models, LLMops addresses the unique characteristics of LLMs such as their large size complex training requirements and high computational demands [1]
and as Nvidia[2] defines it as a subset of the broader GenAIOps paradigm, focused on operationalizing transformer-based networks for language use cases in production applications. Language is a foundational modality that can be combined with other modalities to guide AI system behavior. For example, multimodal systems combine text and image data for visual content production.
The LLMOps workflow
According to Google [1] LLMOps involves a number of different steps, including:
- Data collection and preparation: LLMs require large amounts of data to train. This data must be collected and prepared in a way that is suitable for training the model.
- Model development: LLMs are developed using a variety of techniques, including unsupervised learning, supervised learning, and reinforcement learning.
- Model deployment: Once a LLM has been developed, it must be deployed to a production environment. This involves setting up the necessary infrastructure and configuring the model to run on a specific platform.
- Model management: LLMs require ongoing management to ensure that they are performing as expected. This includes monitoring the model’s performance, retraining the model as needed, and making sure that the model is secure.
Benefits of LLMOps [1]
- Performance: tunes and optimizes LLMs so they respond faster and more accurately in production.
- Scalability: gives you a flexible framework to handle growing traffic, bigger models, and shifting requirements without rewriting everything.
- Risk reduction : catches issues early through monitoring, guardrails, and security checks before they turn into outages or data leaks.
- Efficiency: automates the boring parts of the LLM lifecycle (data prep, deployment, monitoring) so your team spends less time on glue code and more time on what matters.
- GenAIOps as Nvidia [2] mentioned : GenAIOps encompasses MLOps, code development operations (DevOps), data operations (DataOps), and model operations (ModelOps), for all generative AI workloads from language, to image, to multimodal. Data curation and model training, customization, evaluation, optimization, deployment, and risk management must be rethought for generative AI
GenAIOps capabilities include:
- synthetic data management
- embedding management
- agent/chain management
- Guardrails
- prompt management
the transition to LLMs means we need to change how we monitor changes in data and focus more on understanding the subtleties of Natural language and human intent. the unit of logic has moved from the code to prompt. the main problem with GenAI is hallucination, we mitigate this using RAG which grounds the model with facts by fetching relevant context from entreprise documents . in this architecture the llm is not a database but a reasoning engine.
New Lifecycle: (RAG)
In this new paradigm, the lifecycle expands. we are no longer just managing a model; we are managing the Context This introduces the Vector-Retrieval Skew: a situation where your vector database index becomes out of sync with your primary data sources, leading the “reasoning engine” to provide outdated or incorrect facts. Managing this requires the same iterative process for traditional pipelines, but applied to embedding quality and retrieval accuracy [read more about RAG here ]
and to manage the production mode of GenAI, architects deploy a GenAI API gateway as shown in the Fig below. this infrastructure layer handles the operational overhead, prompt versioning, rate limiting, cost tracking across different providers and the enforcement of guardrails to filter adversarial inputs or unsafe outputs
In LLMOps, evals are the new unit tests. Every prompt change or model swap must be benchmarked against them to ensure the system is growing rather than just changing. The main evaluation strategies are:
- Golden datasets: curated input/output pairs representing ideal behavior, run on every change
- LLM-as-a-Judge: using a stronger model (like GPT-4 or Claude) to score outputs on criteria like relevance, faithfulness, and tone
- Human evaluation: domain experts reviewing samples, expensive but still the gold standard
- Red-teaming: adversarial prompts designed to break guardrails and surface unsafe outputs
- “For a software engineer to become an AI engineer, the mental approach has to be different: Shift from code mindset to data mindset. It’s a game of experimentation, iterations and growing a system. It’s not a one-time build.”
Architecture shift : orchestrating compound systems
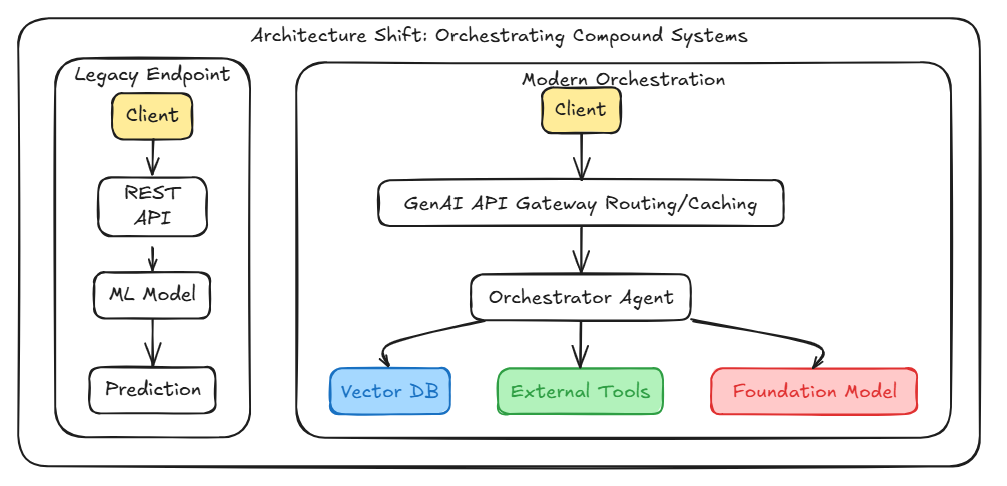
We are moving away from simple REST APIs that serve static predictions. Today’s GenAI architecture requires an API gateway to handle routing, caching, and guardrails, which then feeds into an orchestrator that interacts with vector databases and foundation models dynamically.
GenAI API Gateway: for ease of development, ease of switching models, logging, monitoring metrics, alerting, cost tracking… The core idea of agents is to use a language model to choose a sequence of actions to take.
LLMOps vs MLOps
| Category | MLOps | GenAIOps / LLMOps |
|---|---|---|
| Core Focus | Model Training & Tuning | Model Interaction & Context |
| Key Asset | Feature Stores | Vector Databases & Embeddings |
| Data Management | Tabular & Structured business data | Unstructured data (Text, Video, Audio) |
| Evaluation | Standard deterministic metrics (Accuracy, F1 Score) | ‘LLM-as-a-Judge’, output safety, hallucination rates, and prompt versioning |
Traditional MLOps was all about structured data, managing feature store and tracking metrics like accuracy
LLMOps; a whole different beast : now we are dealing with unstructured text, managing prompts like code and using vector databases and building guardrails that keeps those powerful models to not go off the rails
a new set of problems to solve : we are not tunning models anymore, we are managing embeddings for rag systems or versioning our prompts and detect when exactly our model hallucinate , how to build a reliable system when the outputs are not guaranteed to be the same twice
LLMOps is not replacing MLOps it is just building right on top of it
all those fundamentals about data quality , monitoring and automation are much important than ever
as these ai systems become more and more creative , unpredictable the job is now a bit different, the challenge is not just managing the lifecycle of the model , the real task is designing systems to not just manage but trust AI
In very few short years we have moved from XGboost to transformers and the next architecture might be on the horizon. however the fundamentals of robust system design are constant. Reliability, scalability and maintainability are the only things that survive a model’s obsolescence
As we evaluate our pipelines today we can ask ourselves: is our current infrastructure designed to facilitate the iterative process required for long-term survival or have you built a static monument to a model that will be irrelevant in 6 months?
Consider this the foundation. There’s a lot more to dig into, piece by piece.
References
- [1] Google cloud : what is LLMOps
- [2] Nvidia : Mastering LLMs techniques
- [3] Human-centric ML infra @netflix
- [4] Chip Huyen; Designing Machine Learning Systems (O’Reilly, 2022)
- [5] Stanford MLSys Seminar

(END)